
Welcome to a very dated ‘small slice of web programming’ page. This page contains some information you might find useful if you ever play with the nuts and bolts of web programming via PHP. It also contains a few SQL queries for WordPress sites you might find useful.
I’ve long since moved on to using WordPress without the low-level tinkering the first portion of this page contains, and I recommend it to you as well, as doing so will save a bunch of time in the long run.
One of the items I fought with back in that stone age is prototyping and building this website. The engineer in me wanted a method of testing it on my machine, then having it work flawlessly when it was uploaded to my ISP’s servers.
A problem with a straightforward implementation of a site is that when testing it on your own machine, the links are not the same as those needed when the page goes live. For instance, the main webpage might be on “D:\Documents\website\index.html”, whereas on the web this needs to point to “http:\\www.randommonkeyworks.com\index.html.” This is not a problem if you do every link as a relative link, but common headers, footers, and menus will not work correctly site-wide using relative links — the only links that will work are those at the same directory level as the page you originally created the relative link on.
Another design issue is I wanted a method of quickly changing the major design elements on all (or almost all) of the pages on the site, so that it is easy to make everything have the same look and feel.
After a lot of study and false starts, success was mine!
As indicated, the solution I settled on back then involved PHP. In conjunction with Apache, PHP allows one to completely build the site on their computer, check all the links, and then have everything work correctly when it is uploaded to their ISP.
Before I get into the programming technicality, let me quickly outline installing Apache and PHP.
Matthew Phillips has specified how to install these programs in an article on devarticles.com. It is not necessary to install MySQL for the work we are doing, but if you want a database on your site, and your host allows it on their end, feel free to put it on your computer as well. (To install WordPress locally, you will need a database.)
The point I want to add to Phillips’ instructions is that if you use the .msi installer when installing the newer versions of PHP, you don’t have to go through the hassle of setting up Apache to integrate PHP – the installer will do it for you. But if you want to put your website on a different directory than the default Apache location, you will need to modify the httpd.conf file. (I recall that the even newer versions of WAMP don’t use httpd.conf in the same way, so more research on your end may be called for.)
Now for the programming.
The first of my design goals can be accomplished by creating a variable that points to the appropriate document root. As that variable is held in a file, two different versions of that file (one on my ISP’s website, and the other on my hard drive) allow my site to work differently depending upon where it is located.
Of course, that is not all there is to it, as many on-site links within my pages need to be modified. (By ‘on-site link’ I mean a link that points to a page within my own site, not one that goes elsewhere.) Not all links need to be changed, because you can still use relative links for many portions of the code, but all links in the common header and footer files do have to be PHPd, as it were.
By ‘PHPd’, I mean that those links need to be inserted as a PHP command. In my case, a link to my book is actually encoded like this in html:
<?php echo "<a href='".$workRoot."latd/latd.php'>LATD</a><br>"; ?>
This causes the server (Apache on my machine, or whatever my ISP uses on their machine) to parse this, and insert the value of the ‘workRoot’ variable before the “latd/latd.php”.
That variable is placed in a file that is loaded in the beginning of every page, before the common header file. In my case, the file is called ‘rmwVars.php’, and it looks like:
<?php //Uncomment the appropriate lines. For my computer and the web, $docRoot=$_SERVER["DOCUMENT_ROOT"]."/"; //Don't really understand why we have to have two different //ways to refer to the same address, but for my computer: //$workRoot="http://localhost/"; //For the website: $workRoot = "http://www.randommonkeyworks.com/"; ?>
I don’t recall the exact reasons for having two variables that are so closely related, but looking through a page of code, I see that ‘workRoot’ is used when inserting links to other pages, and ‘docRoot’ is used when inserting header and footer files. I do recall that that lesson involved a lot of grumbling on my part, as well as some profanity being used, but I got it to work in the end, and that is all that matters.
You can probably tell that on my computer, the ‘$workRoot’ variable under the ‘//For the website:’ note is commented out, and the other variable is uncommented.
For your information, the line for inserting the common header reads:
<?php include ($docRoot."common/header.php"); ?>
Before continuing, I should mention a fact that caused a couple hours of frustration on my part. When originally trying to get PHP to work on my ISP, nothing I did was successful, so I gave up on it, and continued using an older, and vastly inferior method to this one. (It involved shtml and Javascript, and I was very glad to be rid of it.) A year or two later I had a chance to get back to this, and tackle it again. But the same thing happened — PHP just wouldn’t work, even though I did exactly what the examples I was looking at said to do.
Finally, I called my ISP, and asked what was going on. A technician and an hour later, I finally found out that all that was needed was to give the page with the script the extension of ‘.PHP.’ Duh! But I didn’t feel too bad, because a) that fact was never mentioned on any of the PHP example pages I came across, and b) it took people who should have known this an hour of their own to figure it out.
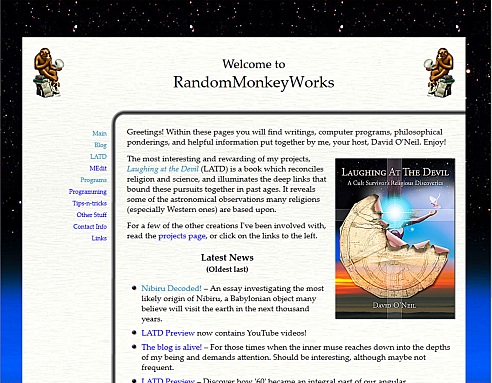
And with that, I believe I have covered enough that you can figure out how to create your own site in the same manner, if you choose to. Even though I haven’t covered the header and footer files in detail, you should be able to figure out what goes into them, and do something similar. For your information, the header includes the side banner with links in the following screen shot, and the footer basically only has the copyright notice in it. (It also closes some tables that were started in the header, but maybe I shouldn’t mention that, just in case you happen to be a table purist. A lot of study didn’t reveal how to create the design more easily using straight CSS.)
For reference sake, here’s a couple SQL queries for site maintenance I’ve used in the past. The first (found at http://wordpress.org/support/topic/how-to-empty-trash-with-2000-posts-at-once, empties the trash:
DELETE p FROM wp_posts p LEFT OUTER JOIN wp_postmeta pm ON (p.ID = pm.post_id) WHERE post_status = 'trash'
While we are doing that, here’s a method to remove revisions, originally found at http://blog.andreineculau.com/2008/07/delete-wordpress-26-revisions/:
DELETE a,b,c FROM wp_posts a LEFT JOIN wp_term_relationships b ON (a.ID = b.object_id) LEFT JOIN wp_postmeta c ON (a.ID = c.post_id) WHERE a.post_type = 'revision'
Of course, turning revisions off should also help. I have, but it doesn’t seem to have taken hold; maybe one must log out and back in? Shouldn’t be the case, but because this post is meant as a reference in the future, the wp-config.php file setting is:
define ('WP_POST_REVISIONS', 0);Happy coding!